What is OCR Analysis in Digital Forensics Investigations?


Optical Character Recognition (OCR) is a technology revolutionizing digital forensics techniques by turning non-searchable documents into actionable evidence. This technology was introduced in 1974 to extract the text from scanned documents, images, and handwritten notes. With the help of this advanced technology, a digital forensic examiner can easily analyze the digital evidence into readable form.
In digital evidence collection in cybersecurity, crucial evidence often exists in formats that aren’t easily searchable, such as scanned contracts, handwritten notes, or screenshots of chat conversations. Before this technology, people used to retype the text manually to make the document digital. However, with time, OCR has emerged as a more advanced technology, and today it delivers results that are near-perfect accuracy.
This technology has become an indispensable tool for forensic data analysis that enables the forensics professional to uncover the hidden evidence, authenticate documents, or recover erased text. OCR enhances the efficiency of the forensic document examination process.
But how exactly does OCR work in digital forensics? What are the challenges that come with its use? And how can forensic professionals maximize its use? And how can forensic professionals maximize their potential? let’s discuss all these factors of OCR Forensics through this guide in detail.
What is OCR Analysis in Digital Forensics?
OCR stands for optical character recognition is an image text recognition technology that is designed to extract data from scanned documents, camera photos, and image-only PDFs. The OCR reader technology extracts individual letters from an image, assembles those letters into words, and then arranges those words into sentences, allowing for editing and access to the original text.
Furthermore, OCR is most frequently used to convert paper-based legal or historical documents into PDF files that can then be edited, formatted, and searched. Additionally, using the best open source OCR models makes the digital examination easier and can search for keywords in a PDF as well.
Early OCR systems struggled with the accuracy of data and often misinterpreted handwritten or degraded text. Today, thanks to machine learning and artificial intelligence, OCR can process complex documents with high precision. There are so many modern forensic investigation tools that use OCR to analyze scanned documents analysis, detect tampered evidence, and extract text from various digital formats.
Making use of OCR technology means saying ‘Good Bye’ to inevitable inaccuracies and typing errors. But how is it possible? Let’s have a look at the working of OCR to better understand it.
Applications of OCR in Digital Forensic Investigations
OCR Optical Character Recognition technology is transforming digital forensic investigations by making non-searchable text accessible, analyzable, and verifiable.
Forensic investigators deal with a vast amount of digital evidence, including scanned documents, handwritten notes, screenshots, and image-based text. OCR plays a crucial role in extracting valuable information from these sources, enabling fast and accurate forensic analysis.
1. Document Analysis in Forensics
OCR allows forensic examiners to convert scanned contracts, legal documents, financial records, and case files into searchable text. This eliminates the need for manual review, significantly reducing investigation time while improving accuracy.
2. Image Analysis in Digital Forensics
Many pieces of evidence, such as photographs of crime scenes, phone screenshots, and scanned receipts, contain crucial textual information. OCR extracts and digitizes this data, making it easier to analyze and cross-reference with other evidence.
3. Handwriting Recognition Forensics
Advanced OCR tools can recognize and analyze handwritten documents, signatures, and notes. This is particularly useful in fraud investigations, identity verification, and forgery detection.
4. Email and Chat Forensics
Cybercrime investigations often involve screenshots of email threads, chat messages, and social media conversations. OCR converts these images into text, allowing forensic analysts to perform keyword searches and identify critical evidence.
5. Criminal Records and Historical Data Extraction
Forensic agencies frequently deal with archived case files, printed records, and old government documents. OCR Optical Character Recognition helps digitize and organize this information, ensuring easy retrieval and analysis in future investigations.
OCR’s ability to process varied text formats makes it an indispensable tool in forensic evidence processing. By unlocking hidden data, it enhances accuracy, speeds up case resolution, and supports legal proceedings with verifiable digital evidence management.
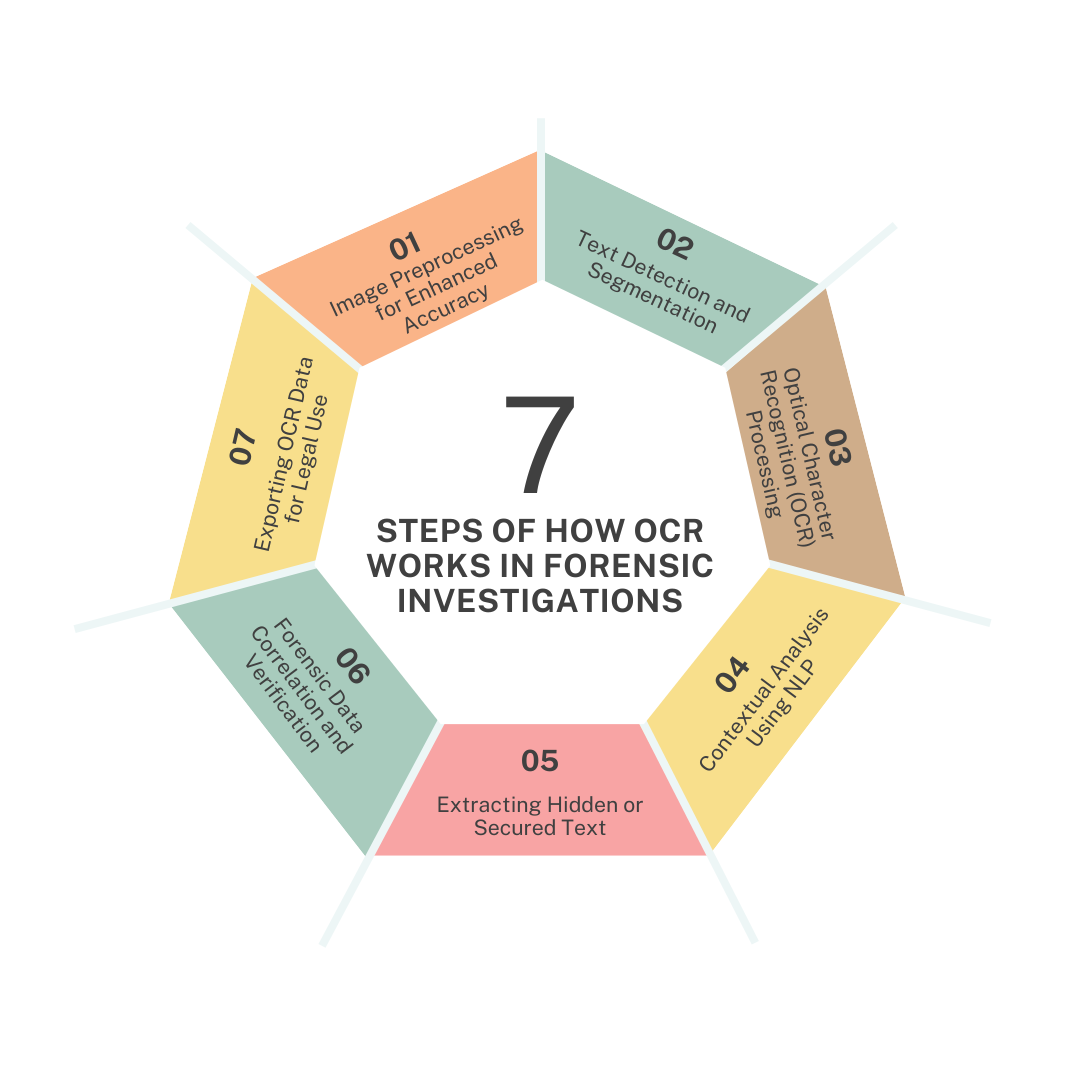
How Does Optical Character Recognition (OCR) Work?
OCR uses by step-by-step process to identify and extract the text from a photo/picture.
First, with the help of OCR technology, the image is thoroughly scanned.
The scanned-in image is then examined for bright and dark parts, with the light areas being classified as the background and the dark areas as characters that need to be recognized.
Numerological or alphabetical digits are found after processing the black areas. During this phase, it usually focuses on one character, word, or section of text at a time. After that, the characters are recognized using one of two algorithms. One is pattern recognition or feature recognition.
Importance of OCR Technology in Digital Forensics
Businesses nowadays are required to provide electronically stored information upon request, and having a system in place that makes all data created in any original format searchable substantially speeds up the process of finding information. The capability that OCR achieves in this aspect cannot be achieved by just scanning documents. Thus, OCR plays an important role and is widely used in online investigations.
Companies may now find information more quickly since OCR can quickly transform photographs or any paper-based data into searchable and readable digital files.
With OCR reader technology, you may categorize and search digitized content by keywords, names, dates, etc., for better information governance. And, particularly, searchability has become very important while performing OCR in legal documents. Because it;
- Fulfils Court Requirements- In most courts, text searchability is required. Once your papers are eFiled, they can check to see if you employed OCR software during an inquiry.
- Saves Time & Cost- Manually digitizing a sizable volume of paper discovery costs a lot of time and money. OCR helps businesses save time and money.
- Gives Higher Accuracy- OCR reduces problems, including typos, grammatical errors, and poor sentence structure. You can obtain a precise duplicate if necessary.
- Manages Handwritten Discovery- OCR software can process and digitize handwritten legal notes and paper discoveries, which are common in these types of documents.
- Easily Gives Access to Files- OCR makes it easier to find and search for certain terms within big files. When you need to work rapidly or focus on a particularly specific stretch of text, this could be a game-changer.
Here, you’ve come across the phrase ‘OCR Software’ but which is the best one present in the market? Well, it’s none other than MailXaminer. It’s the best Professional Email Forensics Software that incorporates OCR technology to extract evidence from image files.
Now, let’s discuss how you can use this software to examine image files.
How to Examine Photos/Pictures Using The Professional Software?
Here is the step-by-step guide to identifying and examining the textual data from the image files. So, let’s begin!
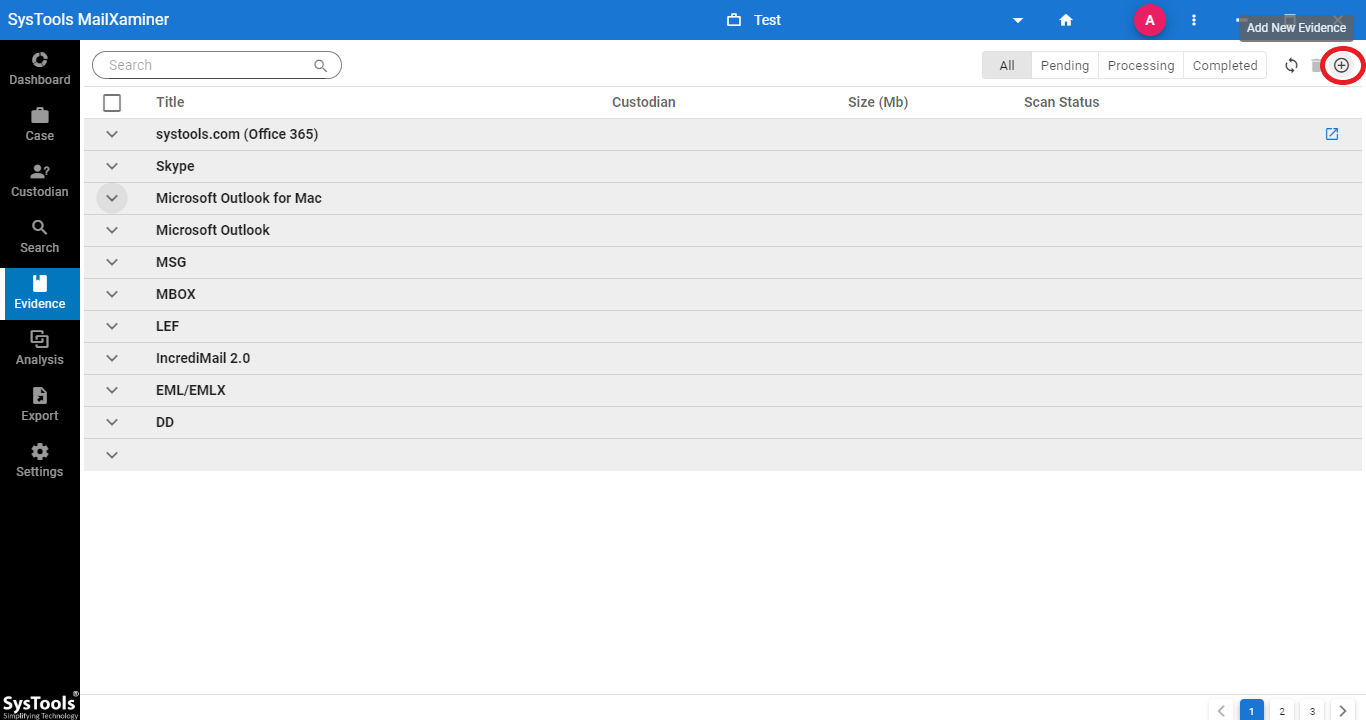
#1 Step: Once the software is launched, you need to add an evidence file to avail of OCR technology. Navigate to the Add-New Evidence button.
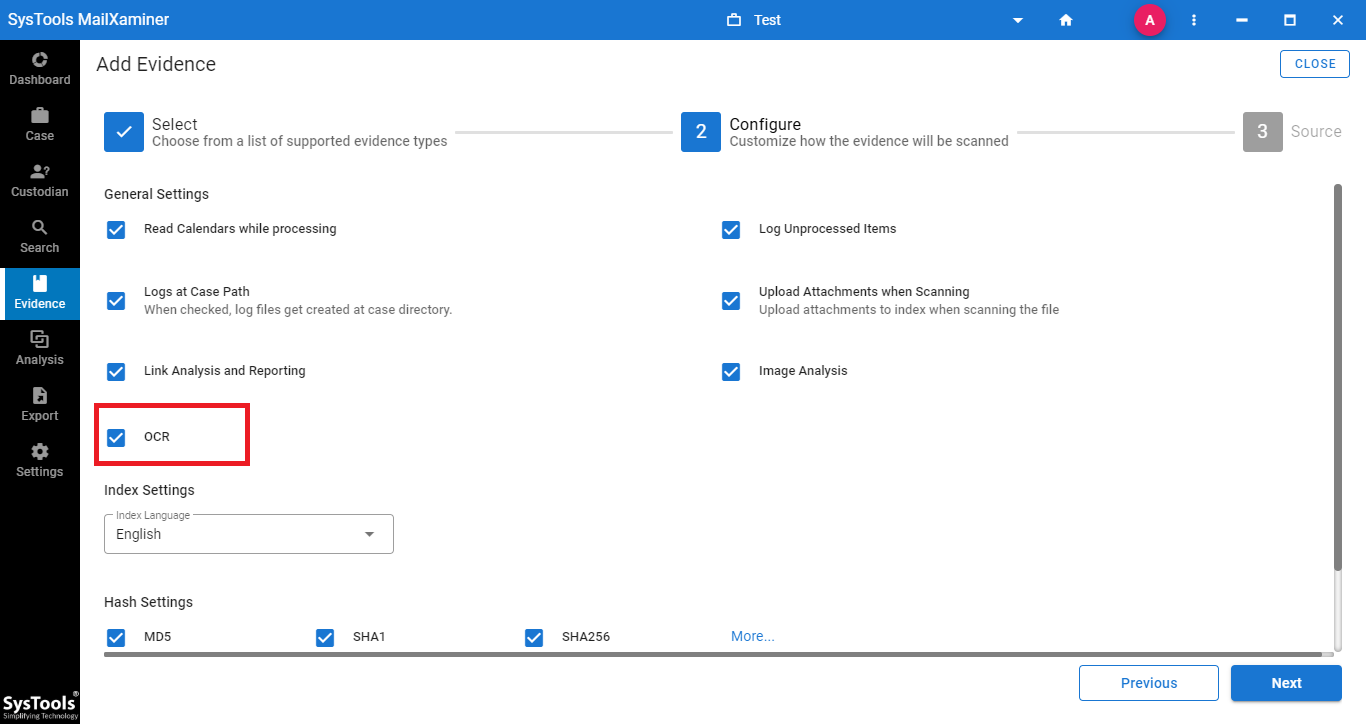
#2 Step: From the Add Evidence screen >> Configure >> check OCR.
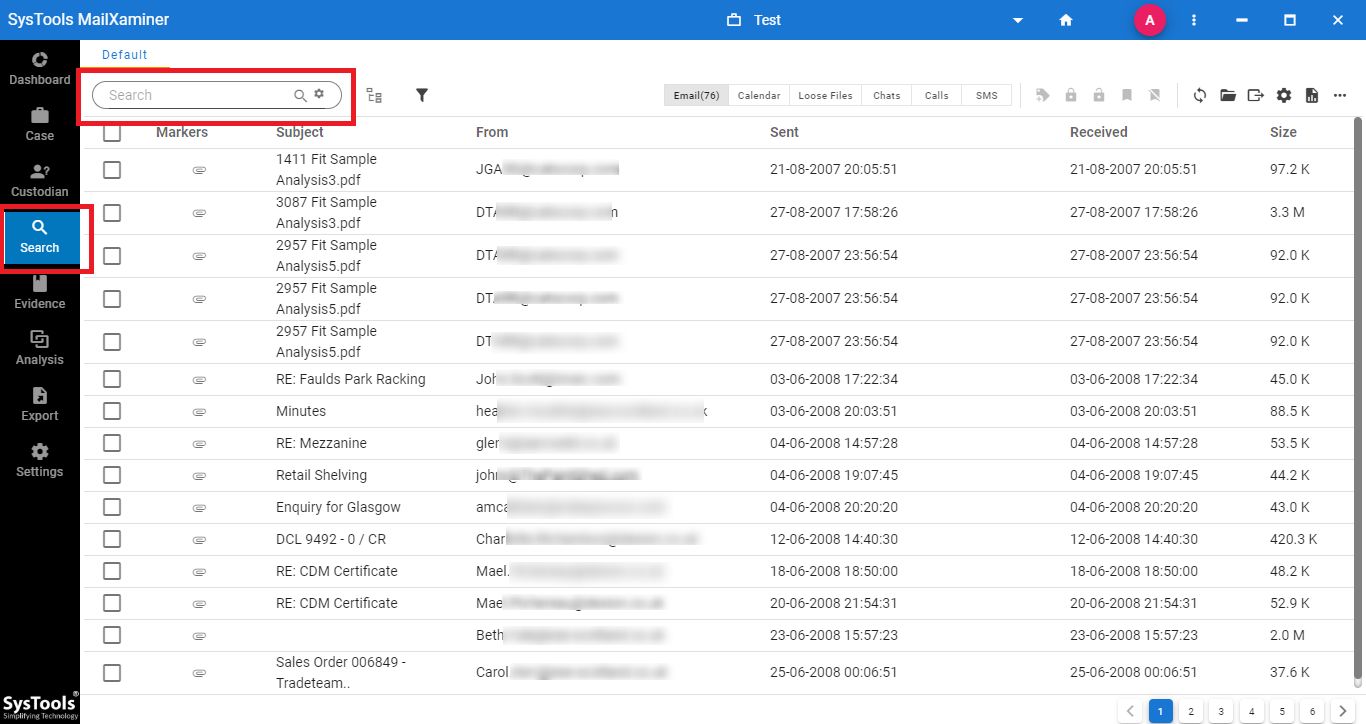
#3 Step: Upon selecting the Search section, the software will provide a detailed preview of all the files
#4 Step: Now, specify the keyword to find from the bulk emails and their attachments using the different Search features.
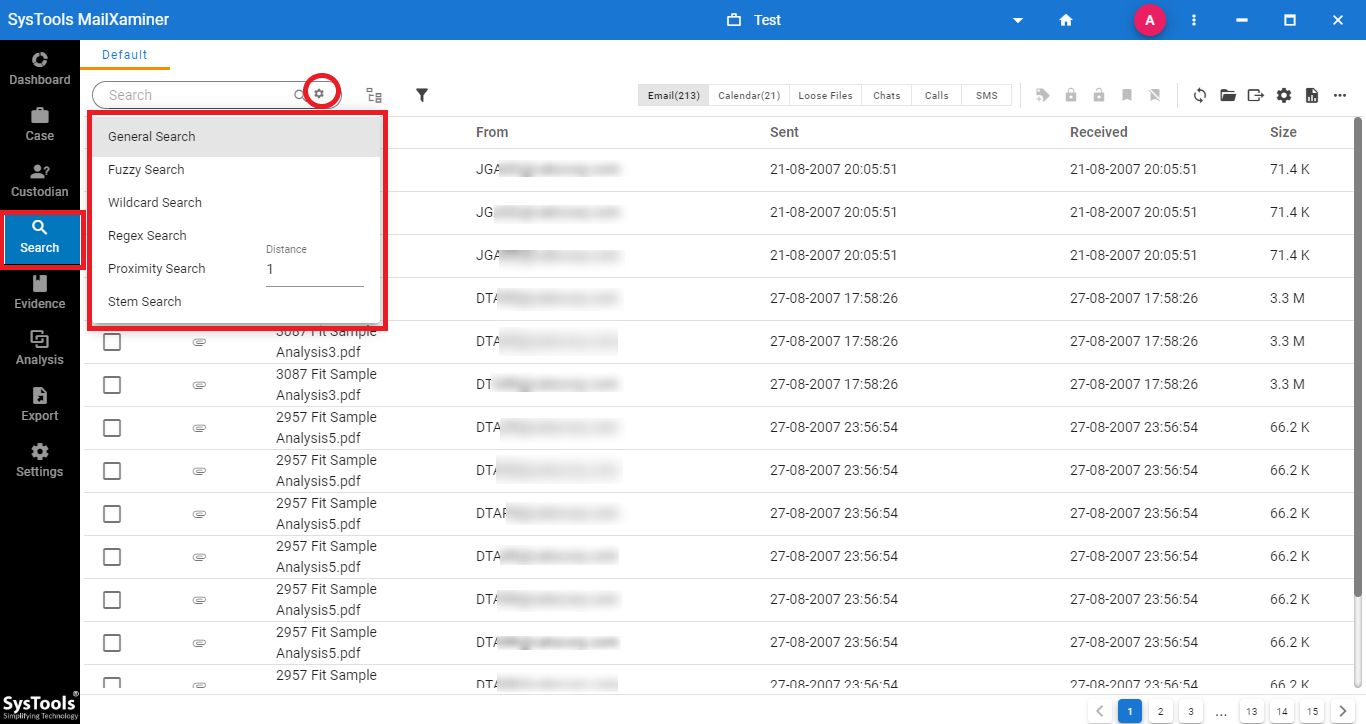
#5 Step: The software will display the matching results, which can be viewed in detail by clicking on any email file.
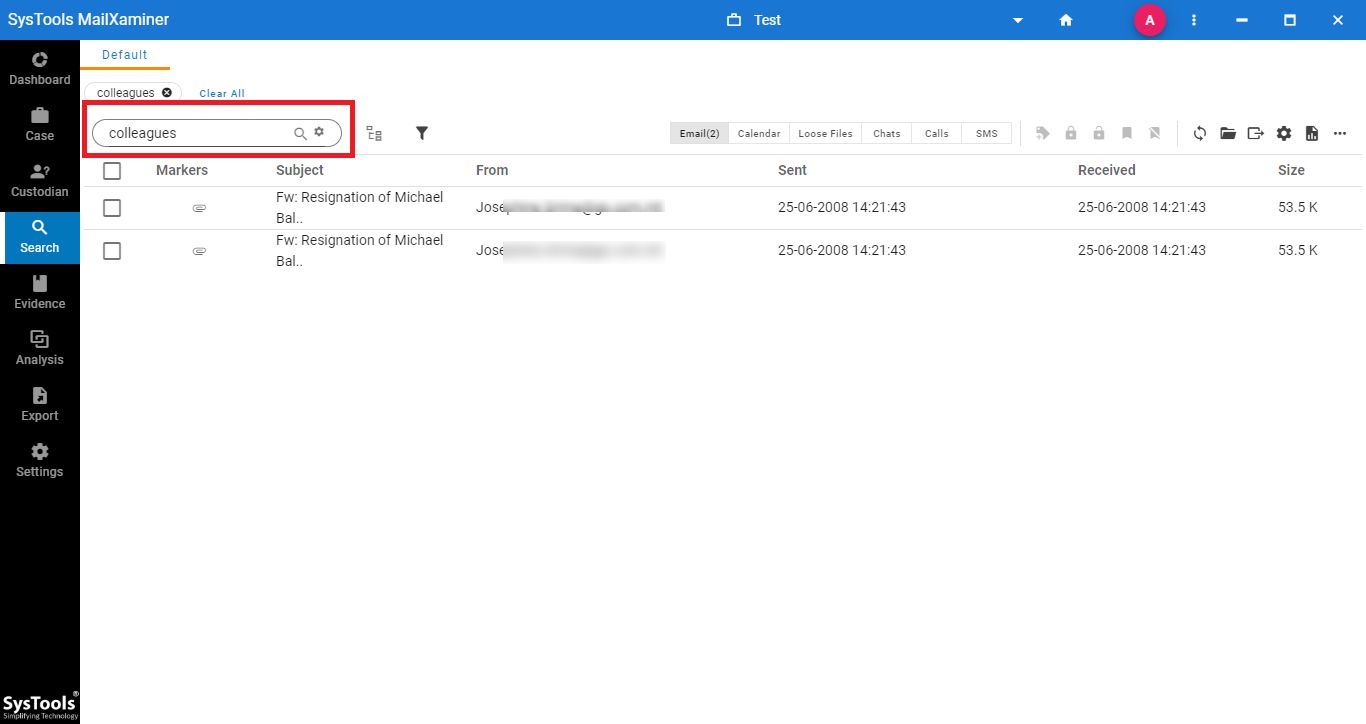
Note: You can apply the pre-defined Media filter to identify the image files at once.
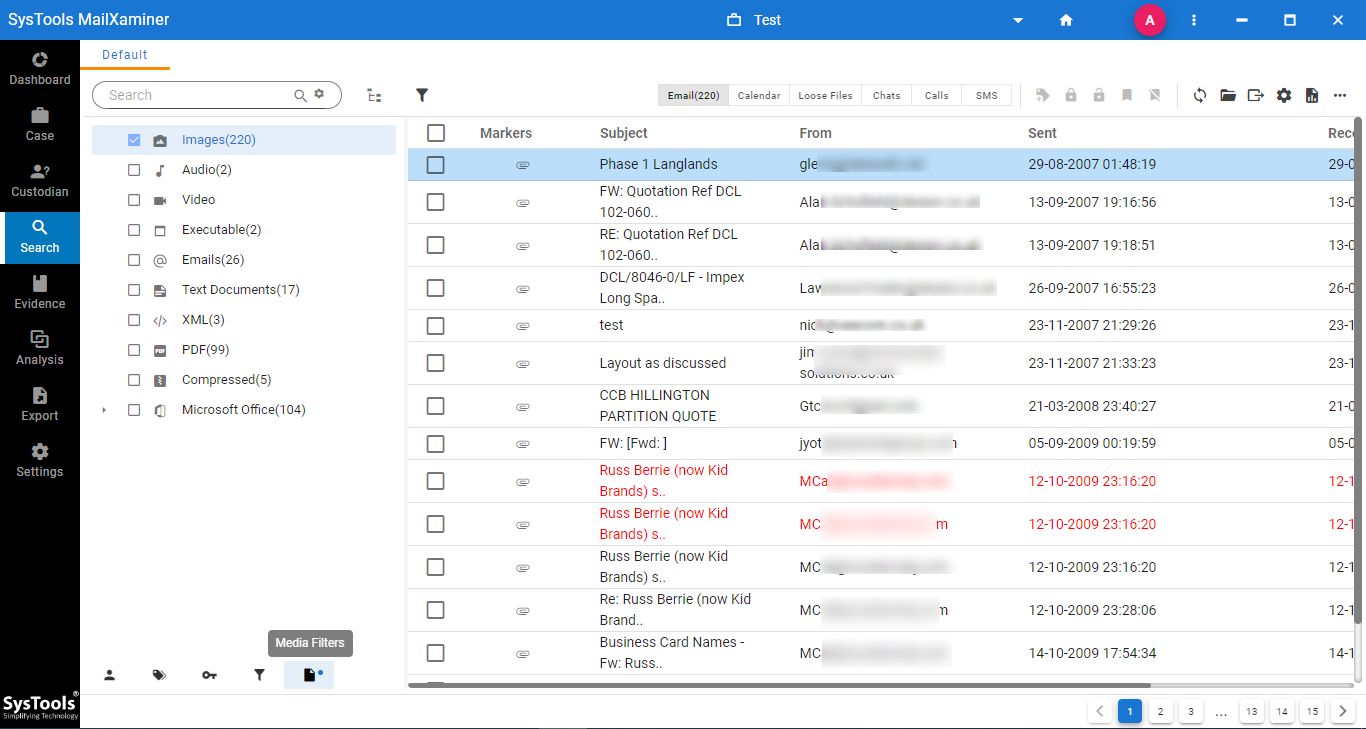
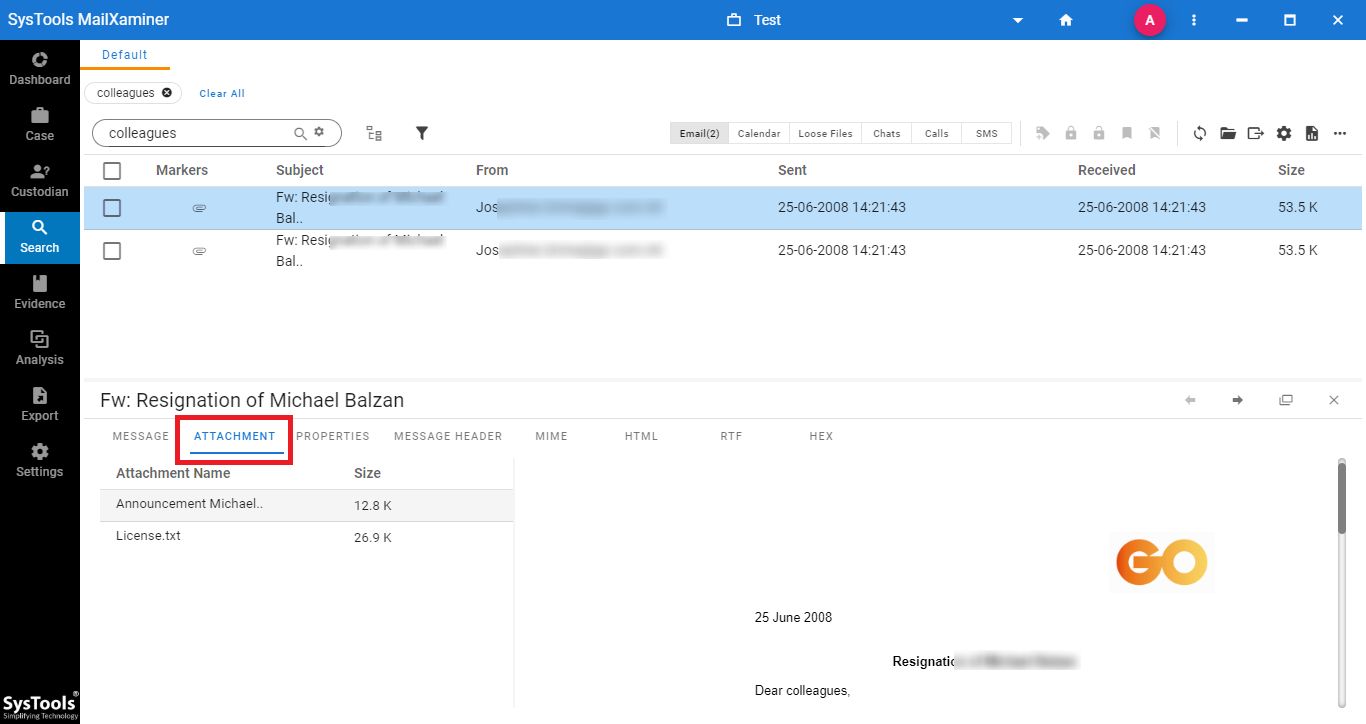
#6 Step: After this, the software will display the file containing the Searched Keyword.
Closing Lines
OCR technology is used to extract textual data from the image and convert it into a machine-reliable text document. While investigating email data files, OCR plays an important role which collects word-based data from uneditable files. Moreover, we have also introduced a proven yet reliable software to perform OCR from the email data files in this blog.