Best Open Source OCR Models: Top OCR Engines Compared in 2026


Introduction to OCR Model Technology
Optical Character Recognition (OCR) is the technology that has come a long way. In the early 1990s, OCR tools could barely recognize printed text reliably. However, in 2026, fast-emerging technology has become modern and advanced in such a way that the best open-source OCR models can identify over 100 languages. The open-source models can handle handwriting, complex layouts, and noisy backgrounds. It is able to process text in real-time for mobile and edge devices. Additionally, it is able to integrate with multimodal AI models that combine vision and language understanding.
Market Fact: The global OCR market is expected to reach $32.9 billion by 2030. Growing at a CAGR of 16.7%. As of May, 2026. Over 65% of enterprise document workflows now include at least one OCR processing layer.
This technology converts printed or handwritten text into machine-readable data. Think about scanning an old book and being able to search for words inside it; that’s OCR in action.
But why go for open source OCR instead of commercial options like ABBYY FineReader or Adobe Acrobat Pro?
This is because open source means Transparency, Customization, Cost efficiency, and Community support.
In 2026, this shift is no longer slight. It is full industry migration,
- Enterprises
- Governments
- Forensic Agencies
Worldwide are now actively replacing proprietary OCR with open-source and multimodal AI engines for speed, privacy, and zero vendor lock-in.
Why Does Choosing the Best Open Source OCR Models Matter?
In 2026, the stakes are higher. Selecting wrong OCR models will ot just cost you accuracy. It will cost you:
- Time.
- Compliance.
- Cour admissible evidence quality.
Whether you are a developer building an automated document pipeline, a researcher digitizing archives, or a forensic investigator analyzing email trails.
Your OCR engine is the foundation everything depends upon. Get it wrong and entire workflow breaks. It is surely an expert digital forensic investigation technique, and choosing the right model impacts the accuracy, performance, integration, and future readiness.
What is the Criteria for Selecting the Best Open Source OCR Models?
Previously, OCR models were designed for reading entire pages and texts. So, here is an outline of questions before judging the open source OCR models:
- How well does it recognize printed and handwritten text?
- Does it support multiple global languages?
- Can it scale to enterprise-level workloads?
- Python, APIs, or modular frameworks?
- Is it actively maintained?
- Can it handle multimodal inputs (images + text)?
- Does it support on-device or edge deployment for privacy-sensitive and air-gapped environments? (Critical for forensic and government use cases in 2026)
Top Open Source OCR Models in 2026 (Ranked & Compared)
Here is the list of the best open source OCR models and cloud OCR Models that are several Vision Language Models (VLMs).
EasyOCR – The developer’s Favorite
This open source OCR model is best for quick integration in Python projects.
- It is powered by PyTorch
- Supports 80+ languages with deep learning accuracy.
- Great for IDs, invoices, and multilingual documents.
- Slightly slower on huge datasets, but very developer-friendly.
Practical Example- The most demanding email forensics software named MailXaminer is trusted by law enforcement agencies across 70+ countries. It integrates EasyOCR to extract hidden text from scanned email attachments, embedded images, and encrypted document trails.
The output is fully searchable, timeline-mapped, and court-admissible.
Additional information- To know more about how it works, follow this complete guide on OCR analysis
Tesseract OCR
It is one of the most widely used open source engines.
- Supports 100+ languages.
- Strong at printed text but weaker with handwriting.
- Great for developers needing stability and wide adoption.
PaddleOCR
It is a lightweight OCR kit which is developed by PaddlePaddle
- It has high accuracy for Chinese and English
- Excellent for complex document layouts analysis and table recognition.
- Perfect for AI/ML research projects.
- Apache 2.0 license
docTR
This is a comprehensive document text recognition library developed by Mindee.
- It uses a transformer architecture for OCR.
- Strong at handwriting recognition.
- It also supports multi-language documents
- Open source and great for researchers.
Microsoft TrOCR
- Uses transformer architecture for OCR.
- Strong at handwriting recognition.
- Supports multi-language documents.
- Open-source and great for researchers.
Donut
It is a free document understanding transformer developed by Clova AI
- Vision + Language Transformer model.
Goes beyond OCR to understand document structure and context.
Ideal for business documents and receipts.
Qwen2.5-VL
It is a powerful multimodal model that excels at visual language tasks.
- Supports text extraction + visual reasoning.
- Handles OCR tasks within broader multimodal workflows.
- Great for AI agents requiring vision + text understanding.
LIama 3.2 Version
This offers OCR as part of its meta’s multimodal AI capabilities.
- It has a general visual understanding
- Contextual text extraction
- Open weighs for developers to fine-tune
TrOCR
- Microsoft’s original transformer-based OCR model.
- Accurate on scanned and handwritten datasets.
- Predecessor of modern multimodal OCR.
OpenAI o1
- Vision + text capabilities.
- OCR is integrated within reasoning pipelines.
- Good at analyzing screenshots and PDFs.
OpenAI GPT-4o & 4o Mini
- Multimodal flagship models.
- Recognize text in images with high accuracy.
- Widely adopted for OCR-style tasks in chatbots and automation.
Gemini 2.5 Pro
No longer in preview Gemini 2.5 Pro is now GA and supports:
- Native PDF OCR with structured JSON output.
- Deep document reasoning.
- Real-time multimodal processing.
It is Google DeepMind’s strongest OCR-capable model to date and the top enterprise pick for document-heavy workflows in 2026.
Gemini 2.0 (Flash, Flash-Lite)
- Optimized for speed and efficiency.
- Great OCR integration for real-time apps.
Florence 2 (Large, Base)
- Microsoft’s vision foundation model.
- Strong OCR integration for enterprise solutions.
Claude Sonnet 4.6 / Claude Opus 4.6 (2026, Current)
Anthropic’s Claude 4 family is a capable lineup for OCR-heavy document understanding in 2026. Claude Sonnet 4.6 delivers an exceptional speed-accuracy balance for high-volume document pipelines.
- Claude Opus 4.6: It is a go to for complex, multi-column, mixed-language forensic documents requiring deep contextual reasoning. Both are production-ready and actively maintained.
- Claude 3.7 Sonnet (2025, Still Relevant)
It is still a strong performer for document OCR tasks. Recommended if your infrastructure is already built around the Claude 3.x API. - Claude 3.5 / Claude 3 (Legacy, Not Recommended for New Deployments)
Functional but superseded. Migrate to Claude 4.x for best results in 2026.
Mistral’s dedicated OCR model is biggest new open-weight entrant of 2026. Optimized for European-language document processing, fully GDPR-compliant, and deployable on-device.
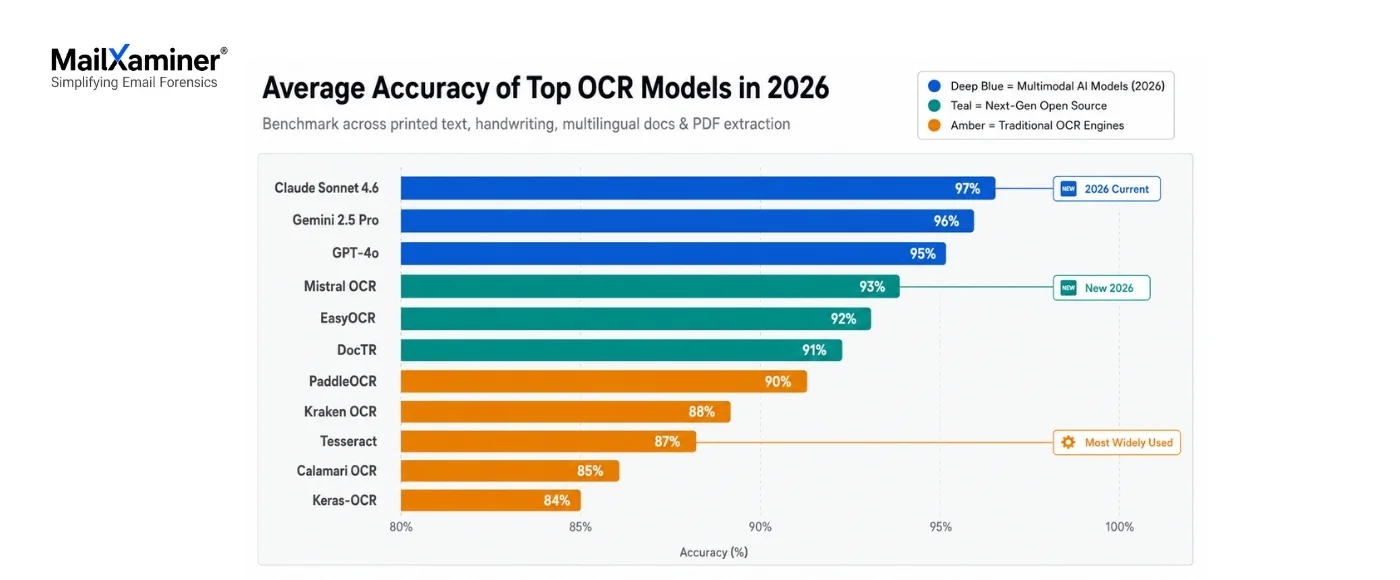
Comparison of the Best Open Source OCR Models
| Model | Accuracy | Speed | Languages | Best Use Case | Community Support |
|---|---|---|---|---|---|
| EasyOCR | High | Fast | 80+ | General OCR | Strong |
| Tesseract | Medium | Slow | 100+ | Documents | Huge |
| PaddleOCR | High | Medium | 80+ | Scene Text | Growing |
| Calamari | Medium | Medium | Limited | Historical | Moderate |
| DocTR | Very High | Fast | Modern | Invoices | Growing |
| Kraken | High | Medium | Flexible | Scripts | Niche |
| Keras-OCR | Medium | Fast | Limited | Research | Small |
| Mistral OCR | Very High | Fast | 50+ | GDPR-compliant enterprise docs | Growing |
| Gemini 2.5 Pro | Very High | Medium | 100+ | Enterprise PDF pipelines | Strong |
Conclusion
In 2026, OCR is no longer a utility. It is an intelligence infrastructure.
The right model depends on your mission:
- Developers building pipelines: EasyOCR, docTR, Mistral OCR
- Researchers & archivists: PaddleOCR, TrOCR, Kraken
- Enterprises & legal teams: Gemini 2.5 Pro, GPT-4o, Claude Sonnet 4.6
Knowing the best OCR model is only half the equation. The other half is what happens to that extracted text next. If your work involves email evidence, legal discovery, or digital investigation. Raw OCR output is useless on its own. You need a platform that takes that extracted text and makes it searchable, filterable, timeline-mapped, and court-admissible.
That is exactly what professional tools are built for.